Delta-RS & DuckDB: Read and Write Delta Without Spark
I have used Apache Spark (often as Azure Databricks) for some years and see it as a sledgehammer in data processing. It is a reliable tool built on JVM, which does in-memory processing and can spin up multiple workers to distribute workload to handle various use cases. It does not matter: whether small or considerable datasets to process; Spark does a job and has a reputation as a de-facto standard processing engine for running Data Lakehouses.
There is an alternative to Java, Scala, and JVM, though. Open-source libraries like delta-rs, duckdb, pyarrow, and polars often written in more performant languages. These newcomers can act as the performant alternative in specific scenarios like low-latency ETLs on small to medium-size datasets, data exploration, etc.
This article is a form of POC exploration with a bit of benchmark to see what is currently possible.
So why Delta-RS and DuckDB?
- Delta-RS library provides low-level access to Delta tables in Rust, which data teams can use in data processing frameworks. It also provides bindings to another higher-level language – Python.
- DuckDB is an open-source in-process SQL OLAP database management system.
The solution is a combination of those two libraries with Apache Arrow as the columnar in-memory format:
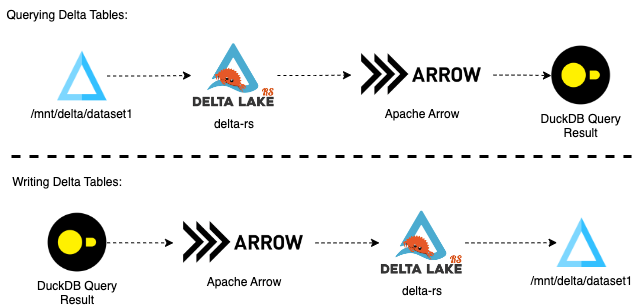
Prepare a clean environment.
First thing first, let’s prepare the clean Python environment. I am going to run the code on Apple M2 Pro; however, all snippets must be compatible with Linux and WSL of Windows 10/11:
mkdir delta-rs cd delta-rs python3.10 -m venv .venv source .venv/bin/activate touch delta-rs-exploration.ipynb code .
When VS Code is launched, choose a recently created Python environment in the notebook kernel selection:
That’s it, the sandbox is ready, and we are good to go.
Generate Sample Dataset using PySpark.
We must generate sample data first to proceed with delta-rs testing. So let’s first install pyspark and dbldatagen. The last one is a Databricks Labs project and data generation tool.
%pip install pyspark==3.3.1 %pip install dbldatagen==0.3.4 %pip install pyparsing==3.0.9
The next step is to initialize spark. The following code will run spark in the minimalistic version to avoid UI overhead:
from pyspark.sql import SparkSession
spark_jars = (
"org.apache.spark:spark-avro_2.12:3.2.1"
",io.delta:delta-core_2.12:2.1.0"
",com.databricks:spark-xml_2.12:0.14.0"
)
spark = (
SparkSession.builder.master("local[*]")
.appName("MyApp")
.config("spark.jars.packages", spark_jars)
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config(
"spark.sql.catalog.spark_catalog",
"org.apache.spark.sql.delta.catalog.DeltaCatalog",
)
.config("spark.ui.showConsoleProgress", "false")
.config("spark.ui.enabled", "false")
.config("spark.ui.dagGraph.retainedRootRDDs", "1")
.config("spark.ui.retainedJobs", "1")
.config("spark.ui.retainedStages", "1")
.config("spark.ui.retainedTasks", "1")
.config("spark.sql.ui.retainedExecutions", "1")
.config("spark.worker.ui.retainedExecutors", "1")
.config("spark.worker.ui.retainedDrivers", "1")
.config("spark.driver.memory", "16g")
).getOrCreate()
Since spark must be installed and initialized by now, it is time to generate a simple dataframe with ten million rows of sample data using dbldatagen
import dbldatagen as dg
from pyspark.sql.types import IntegerType
row_count = 10 * 1000 * 1000
test_data_spec = (
dg.DataGenerator( spark, name="test_data_set1", rows=row_count, partitions=4,
randomSeedMethod="hash_fieldname", verbose=True, )
.withColumn("purchase_id", IntegerType(), minValue=1000000, maxValue=2000000)
.withColumn("product_code", IntegerType(), uniqueValues=10000, random=True)
.withColumn(
"purchase_date",
"date",
data_range=dg.DateRange("2017-10-01 00:00:00", "2018-10-06 11:55:00", "days=3"),
random=True,
)
.withColumn(
"return_date",
"date",
expr="date_add(purchase_date, cast(floor(rand() * 100 + 1) as int))",
baseColumn="purchase_date",
)
.withColumn("name", "string", percentNulls=0.01, template=r'\\\\w \\\\w|\\\\w A. \\\\w|test')
.withColumn("emails", "string", template=r'\\\\w.\\\\w@\\\\w.com', random=True,
numFeatures=(1, 6), structType="array")
)
df_test_data = test_data_spec.build()
And then check the dataframe content before materializing it:
# returns: 10.0 df_test_data.count() / 1000_000 df_test_data.limit(5).show(truncate=True) """ +-----------+------------+-------------+-----------+--------------------+--------------------+ |purchase_id|product_code|purchase_date|return_date| name| emails| +-----------+------------+-------------+-----------+--------------------+--------------------+ | 1000000| 7503| 2017-10-07| 2017-11-28| pariatur F. ut|[elit.sunt@veniam...| | 1000001| 7740| 2018-04-02| 2018-04-12| ut G. quis|[do.eu@laborum.co...| | 1000002| 6891| 2018-03-14| 2018-03-22|anim H. reprehend...|[irure.aute@velit...| | 1000003| 3751| 2017-12-26| 2018-02-25| test|[nostrud.adipisci...| | 1000004| 8015| 2017-11-05| 2017-12-07| qui laboris|[aute.voluptate@n...| +-----------+------------+-------------+-----------+--------------------+--------------------+ """
Let’s now save it as a delta dataset (generated by pyspark)
df_test_data.write.format("delta").mode("overwrite").save("delta/sample_dataset")
At this point, the sample dataset was generated and materialized. For the sake of the performance comparison between PySpark and DuckDB, I will read it back from Delta and then run a sample analytics query:
df_read_delta = spark.read.format("delta").load("delta/sample_dataset")
df_read_delta.createOrReplaceTempView("sample_dataset")
query = """
select
purchase_date,
count(distinct purchase_id) as purchases,
count(emails) as emails
from sample_dataset
group by purchase_date
order by 2 desc
limit 5
"""
spark.sql(query).show()
"""
output:
+-------------+---------+------+
|purchase_date|purchases|emails|
+-------------+---------+------+
| 2018-08-21| 79148| 82085|
| 2018-08-12| 79132| 82024|
| 2018-02-03| 78976| 81911|
| 2018-04-29| 78913| 81813|
| 2018-05-23| 78897| 81849|
+-------------+---------+------+
"""
The query execution duration was 4.5 seconds on my laptop, and I will execute it eventually, also using DuckDB, to match the performance of data engines.
Run a query on a sample dataset using Delta-RS and DuckDB.
Firstly, let’s add missing libraries. Delta-RS currently has two implementations: in Python and Rust. Because I continue exploring a Python version I have to install and import a package deltalake: It also installs dependencies like pyarrow and numpy if they are missing. In the same step, I also include pandas and duckdb required for querying and data manipulation
%pip install deltalake==0.8.1 %pip install pandas=1.5.0 %pip install duckdb==0.7.1
Let’s check if we can use delta-rs to reveal the dataset’s history generated by PySpark
from deltalake import DeltaTable
dt = DeltaTable("delta/sample_dataset")
dt.history()
"""
[{'timestamp': 1682098489708,
'operation': 'WRITE',
'operationParameters': {'mode': 'Overwrite', 'partitionBy': '[]'},
'isolationLevel': 'Serializable',
'isBlindAppend': False,
'engineInfo': 'Apache-Spark/3.3.1 Delta-Lake/2.1.0',
'operationMetrics': {'numFiles': '4',
'numOutputBytes': '480488931',
'numOutputRows': '10000000'},
'txnId': 'ee54da7d-4dad-4652-b24f-813d6cf5633f'}]{'type': 'struct',
'fields': [{'name': 'purchase_id',
'type': 'integer',
'nullable': True,
'metadata': {}},
{'name': 'product_code',
'type': 'integer',
'nullable': True,
'metadata': {}},
{'name': 'purchase_date', 'type': 'date', 'nullable': True, 'metadata': {}},
{'name': 'return_date', 'type': 'date', 'nullable': True, 'metadata': {}},
{'name': 'name', 'type': 'string', 'nullable': True, 'metadata': {}},
{'name': 'emails',
'type': {'type': 'array', 'elementType': 'string', 'containsNull': True},
'nullable': True,
'metadata': {}}]}
"""
The library also returns schema, while handy Spark’s df.printSchema() is indeed missing:
dt.schema().json()
"""
{'type': 'struct',
'fields': [{'name': 'purchase_id',
'type': 'integer',
'nullable': True,
'metadata': {}},
{'name': 'product_code',
'type': 'integer',
'nullable': True,
'metadata': {}},
{'name': 'purchase_date', 'type': 'date', 'nullable': True, 'metadata': {}},
{'name': 'return_date', 'type': 'date', 'nullable': True, 'metadata': {}},
{'name': 'name', 'type': 'string', 'nullable': True, 'metadata': {}},
{'name': 'emails',
'type': {'type': 'array', 'elementType': 'string', 'containsNull': True},
'nullable': True,
'metadata': {}}]}
"""
Let’s prepare the dataset for querying:
import duckdb pyarrow_dataset = dt.to_pyarrow_dataset() sample_dataset = duckdb.arrow(pyarrow_dataset)
And then eventually query it using the Spark-like syntax of DuckDB:
sample_dataset.filter("purchase_id = 1000000").project("purchase_id, product_code, name")
"""
┌─────────────┬──────────────┬────────────────────┐
│ purchase_id │ product_code │ name │
│ int32 │ int32 │ varchar │
├─────────────┼──────────────┼────────────────────┤
│ 1000000 │ 7503 │ test │
│ 1000000 │ 9981 │ aliquip M. eiusmod │
│ 1000000 │ 5467 │ nisi Z. quis │
│ 1000000 │ 9854 │ test │
│ 1000000 │ 7499 │ test │
│ 1000000 │ 4288 │ test │
│ 1000000 │ 9674 │ NULL │
│ 1000000 │ 3593 │ ipsum laboris │
│ 1000000 │ 4885 │ fugiat C. commodo │
│ 1000000 │ 2343 │ commodo H. in │
├─────────────┴──────────────┴────────────────────┤
│ 10 rows 3 columns │
└─────────────────────────────────────────────────┘
"""
The next step is to run the analytics query that I used earlier in this article:
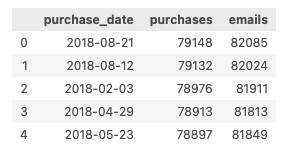
query = """ select purchase_date, count(distinct purchase_id) as purchases, count(emails) as emails from sample_dataset group by purchase_date order by 2 desc limit 5 """ duckdb.query(query) """ ┌───────────────┬───────────┬────────┐ │ purchase_date │ purchases │ emails │ │ date │ int64 │ int64 │ ├───────────────┼───────────┼────────┤ │ 2018-08-21 │ 79148 │ 82085 │ │ 2018-08-12 │ 79132 │ 82024 │ │ 2018-02-03 │ 78976 │ 81911 │ │ 2018-04-29 │ 78913 │ 81813 │ │ 2018-05-23 │ 78897 │ 81849 │ └───────────────┴───────────┴────────┘ """
It was finished in 0.7 seconds in DuckDB versus 4.5 seconds in PySpark.
The query output can also be materialized to the pandas dataframe:
duckdb.query(query).to_df()
Create new datasets using Delta-RS and DuckDB.
Let’s now write the outcome of the query back to the delta lake and check if the dataset exists:
from deltalake.writer import write_deltalake
arrow_table = duckdb.query(query).to_arrow_table()
write_deltalake(
data=arrow_table,
table_or_uri="delta/demo_dataset_groupby_rust",
mode="overwrite",
overwrite_schema=True
)
DeltaTable("delta/demo_dataset_groupby_rust").history()
"""
[{'timestamp': 1682098595580, 'delta-rs': '0.8.0'},
{'timestamp': 1682098622494,
'operation': 'WRITE',
'operationParameters': {'partitionBy': '[]', 'mode': 'Overwrite'},
'clientVersion': 'delta-rs.0.8.0'}]
"""
Check the dataset generated by Delta-RS in PySpark.
As the final exploration, let’s ensure that PySpark can read datasets generated outside and that there are no computability issues:
spark.read.format("delta").load("delta/demo_dataset_groupby_rust").show()
"""
results:
+-------------+---------+------+
|purchase_date|purchases|emails|
+-------------+---------+------+
| 2018-08-21| 79148| 82085|
| 2018-08-12| 79132| 82024|
| 2018-02-03| 78976| 81911|
| 2018-04-29| 78913| 81813|
| 2018-05-23| 78897| 81849|
+-------------+---------+------+
"""
Luckily, this is not the case. Spark can still use delta objects generated outside.
Let’s also check how Pyspark can read metadata of history created by the package outside. This time I install spark’s version of delta:
%pip install delta-spark
I noticed that not all fields of the delta history formed by the side delta writer are available in the PySpark:
from delta import DeltaTable
(
DeltaTable
.forPath(path="delta/demo_dataset_groupby_rust", sparkSession=spark)
.history()
.show()
)
"""
+-------+--------------------+------+--------+---------+--------------------+----+--------+---------+-----------+--------------+-------------+----------------+------------+----------+
|version| timestamp|userId|userName|operation| operationParameters| job|notebook|clusterId|readVersion|isolationLevel|isBlindAppend|operationMetrics|userMetadata|engineInfo|
+-------+--------------------+------+--------+---------+--------------------+----+--------+---------+-----------+--------------+-------------+----------------+------------+----------+
| 2|2023-04-21 19:37:...| null| null| WRITE|{partitionBy -> [...|null| null| null| null| null| null| null| null| null|
| 1|2023-04-21 19:37:...| null| null| WRITE|{mode -> Overwrit...|null| null| null| null| null| null| null| null| null|
| 0|2023-04-21 19:36:...| null| null| null| null|null| null| null| null| null| null| null| null| null|
+-------+--------------------+------+--------+---------+--------------------+----+--------+---------+-----------+--------------+-------------+----------------+------------+----------+
"""
So only essential columns are filled: version, timestamp, operation, and operationParameters.
Some potential use cases
Delta-RS is a relatively young and actively developed library; however, it can already be a helpful addition to the tool stack of the data teams:
- Data Science: The discussed combination of libraries might be beneficial in data exploration because it still offers SQL interface but might provide a more robust response with less involved resources
- Data Engineering: Low-latency ETLs on small to medium-size datasets.
- Cost Saving: Reading and writing Delta Lake datasets in Python without the need for spark, which could be helpful for smaller teams or projects with limited resources.
Conclusion
Delta-RS and DuckDB offer an alternative to spark for querying and writing Delta Lake datasets. With the ability to run analytics queries and create new datasets, these libraries can be a useful addition to a data team’s toolbox. Furthermore, they can provide cost savings for smaller teams or projects with limited resources.