Azure Data Lake gen2 & SQL Server – Getting started with a PolyBase
Imagine a scenario: your team runs SQL Server boxes, has plenty of experience in T-SQL and sometimes needs to dump results of the queries into a data lake. Or, the data is to be age-out and should be placed to an archival location. Or, yet another one scenario – the interactive querying of parquet files by joining them to local relational tables.
Starting with a release of SQL Server 2016 Microsoft delivered the PolyBase – a solution for such cases. This post is about getting started with this feature and run a few demos: data ingestion and data retrieval.
Prerequisites
- SQL Server 2016 or later with installed PolyBase. More information: Install PolyBase on Windows
- Azure Data Lake Gen2 account.
So, what is the Polybase
Let’s start a theoretical part with the official definition:
PolyBase enables your SQL Server instance to process Transact-SQL queries that read data from external data sources. SQL Server 2016 and higher can access external data in Hadoop and Azure Blob Storage.
What is PolyBase?
With a SQL Server 2019 release, the list of external data sources was expanded to Oracle, Teradata, MongoDB, and ODBC Generic Types. In this post, I will focus on connectivity between SQL Server and HDFS based data lakes, like Azure Data Lake gen2.
PolyBase logically acts as a super-set on top of SQL Server Data Engine:

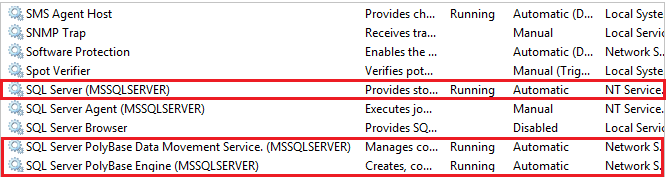
From the infrastructure point of view it is presented by a few extra windows services:

It also worth to mention that while conceptually there are a lot of similarities to the linked server, the PolyBase is still acting differently:
| PolyBase | Linked Servers |
| Database scoped object | Instance scoped object |
| Uses ODBC drivers | Uses OLEDB providers |
| Supports read-only operations for all data sources and insert operation for HADOOP & data pool data source only | Supports both read and write operations |
| Queries to remote data source from a single connection can be scaled-out | Queries to remote data source from a single connection cannot be scaled-out |
| Predicates push-down is supported | Predicates push-down is supported |
| No separate configuration needed for availability group | Separate configuration needed for each instance in availability group |
| Basic authentication only | Basic & integrated authentication |
| Suitable for analytic queries processing large number of rows | Suitable for OLTP queries returning single or few rows |
| Queries using external table cannot participate in distributed transaction | Distributed queries can participate in distributed transaction |
Since the theoretical part is over let’s move to a practical one and have it configured and running
A practical part or how-to get the feature configured
Step 1: Perform an initial configuration of a PolyBase on the instance level
The following script to be executed once to get all necessary options enabled:
IF NOT (SELECT SERVERPROPERTY ('IsPolyBaseInstalled') AS IsPolyBaseInstalled) = 1
PRINT 'Polybase is not installed. Terminating.'
ELSE
BEGIN
-- Command 1: Enable PolyBase on an instance level
EXEC sp_configure 'polybase enabled', 1;
-- Command 2: Set connectivity to support Azure blob storage (WASB driver)
EXEC sp_configure @configname = 'hadoop connectivity', @configvalue = 7;
-- Command 3: Set connectivity to support Azure blob storage (WASB driver)
EXEC sp_configure 'allow polybase export', 1;
RECONFIGURE WITH OVERRIDE
END
The script contains a few commands, it worth to take a closer look on each one and see what kind of exceptions they raise if the configuration has not been executed properly.
The first command in the script enables the feature. If it was not executed or if the instance was not restarted after the execution the following error will appear during data source creation:
Incorrect syntax near ‘HADOOP’.
The second command enables WASB driver. If the feature configured differently, it will result in an error message:
External file access failed due to internal error: ‘Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_Connect. Java exception message: No FileSystem for scheme: wasbs’
The third command enables data ingestion into a Data Lake, so INSERT commands are possible. If this command skip, the INSERT statement will be failed and this error message appears:
INSERT into external table is disabled. Turn on the configuration option ‘allow polybase export’ to enable.
Important: Related services have to be restarted after every time the script was executed:
Step 2: Get a storage account credentials
Since the PolyBase has to deal with Azure Data Lake, it should be able to access it. Following credentials have to be known before we proceed with a database level configuration:
- Storage account name
- Storage account Key
- Container name
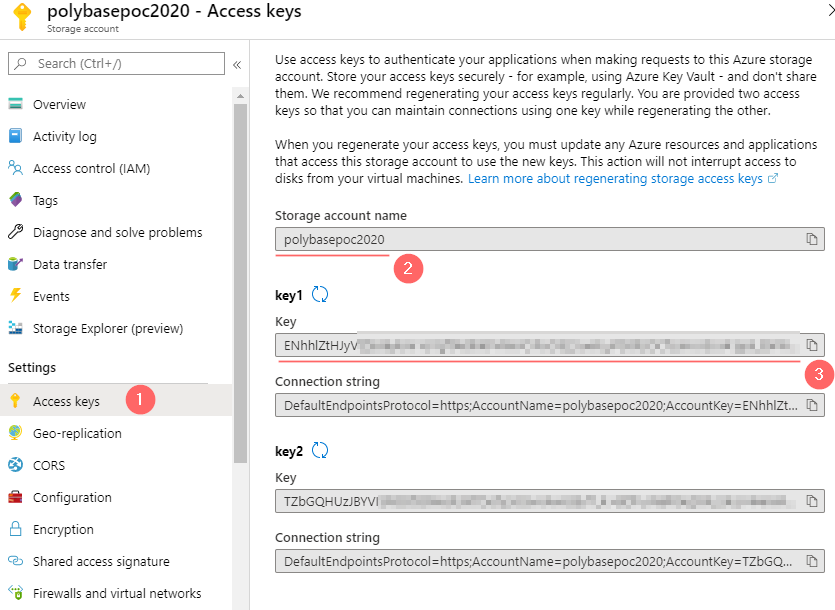
The storage account key can be obtained by navigating to Storage account page -> Settings -> Access keys:
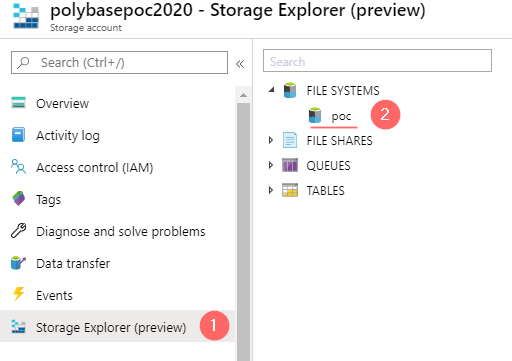
A storage container can be created or enumerated using a built-in Storage Explorer:
Therefore, in my case the credentials are:
- Storage Account Name:
polybasepoc2020 - Storage container:
poc - Storage Account Key:
LongTextAbraCadabra123456LongTextAbraCadabra123456==
By having this information, we can proceed to a database configuration.
Step 3: Configuration of the feature on a database level
Let’s firstly create a blank database PolyBasePoc and a dedicated schema ADLS. This schema will be used later to store external tables:
-- Create a separate database and a schema CREATE DATABASE PolyBasePoc GO USE PolyBasePoc GO CREATE SCHEMA ADLS GO
The second step is to create a master key. This is necessary to store database credentials in an encrypted state:
-- Create a master key to encrypt sensitive credential information CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'PolyBasePOC#Key01'; GO
Then, create a database scoped credential which keeps a storage account key. Note, that IDENTITY attribute is not in use in this example and can contain any value. The value of a SECRET attribute is a storage account key:
-- Create Azure storage credential CREATE DATABASE SCOPED CREDENTIAL AzureStorageKey WITH IDENTITY = 'ADLS_Any_String', Secret = 'LongTextAbraCadabra123456LongTextAbraCadabra123456=='; GO
Another step: the creation of an external data source. The type is set to HADOOP because the Azure Data Lake is an HDFS compatible cloud storage, therefore the PolyBase works with it the same way as with other HADOOP appliances. Note that a location is configured via wasb driver and should use such format: 'wasbs://{storage_container}@ {storage_accountname}.blob.core.windows.net' :
-- Create Azure storage data source
CREATE EXTERNAL DATA SOURCE AzureStorage
with (
TYPE = HADOOP,
LOCATION ='wasbs://poc@polybasepoc2020.blob.core.windows.net',
CREDENTIAL = AzureStorageKey
);
GO
And the final step, which is optional, but required for HADOOP data sources, is a file format definition. In a current example it is a semicolon-delimited text file:
-- Create a file format definition
CREATE EXTERNAL FILE FORMAT DelimitedTextFormat WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR =';',
USE_TYPE_DEFAULT = TRUE));
GO
Step 4: Create an external table
Because all preparations on an instance and database level are done, let’s create a first external dummy table, which contains information about the databases:
CREATE EXTERNAL TABLE [ADLS].[Databases] (
[ID] INT NOT NULL,
[Name] VARCHAR(128) NOT NULL,
[Collation] VARCHAR(128) NULL,
[State] VARCHAR(128) NOT NULL,
[Recovery] VARCHAR(128) NOT NULL
)
WITH (LOCATION='/PolyBase/Databases',
DATA_SOURCE = AzureStorage,
FILE_FORMAT = DelimitedTextFormat
);
The table definition uses defined DATA_SOURCE and FILE_FORMAT objects and configured to write/read data in a Data Lake directory: /PolyBase/Databases. The execution of CREATE EXTERNAL TABLE command without any exception is a signal that a configuration went well and we can proceed to a testing part.
The PolyBase in action
Let’s make a few demo executions to test very basic scenarios: data ingestion and data retrieval.
Demo 1: The data ingestion into the Data Lake:
The data ingestion is a simple INSERT..SELECT T-SQL statement:
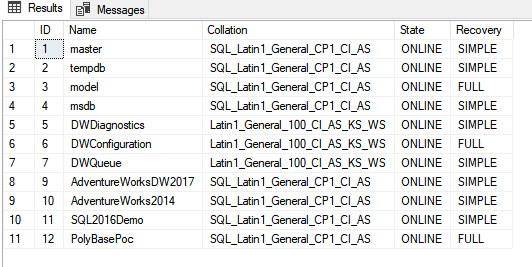
INSERT INTO [ADLS].[Databases] (ID, Name, Collation, State, Recovery) SELECT database_id, name, collation_name, state_desc,recovery_model_desc FROM sys.databases;
The execution results also into a usual output: (11 rows affected).
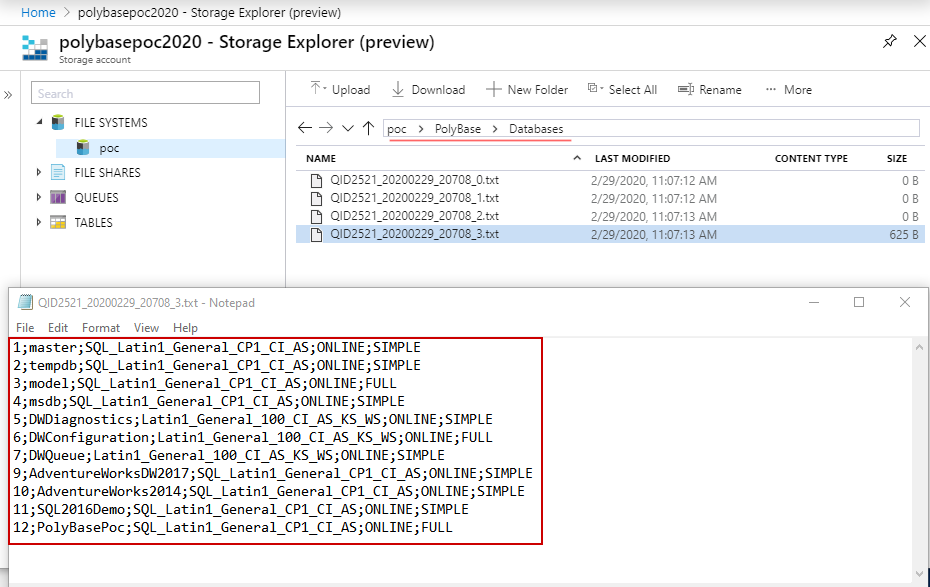
Under the hood, the PolyBase creates directories PolyBase and Databases and splits the dataset into four partitions. Internally, files have a CSV format:
Demo 2: The data retrieval from a Data Lake:
The external table can be queried the same way as a regular one:
SELECT * FROM [ADLS].[Databases]
Final words
This post is about practical aspects of using the PolyBase as the bridge between HDFS storage and SQL Server data engine. It shows how to configure it on the instance and database levels and how the data ingestion and consumption can be done using SQL Server and T-SQL.
Many thanks for reading.