Azure Data Factory & DevOps – Automated Deployment via Azure CLI
In a coming series of posts, I would like to shift a focus to subjects like automation and DevOps. This post will show how the entire Data Factory environment and surrounding services can be deployed by a command line or be more precise, by the Azure CLI.
Such an approach may look tedious and overkilling at a first glance, however, it pays back since it brings nice things like reproducibility, enforcement of standards, avoidance of human mistakes.
Our sample environments
Beside of a plain data factory, it is not uncommon that data engineers use some extra Azure services. Often the landscape also includes a storage account, key vault, etc. All these pieces create together isolated environments for every stage: Development, Acceptance, and Production.
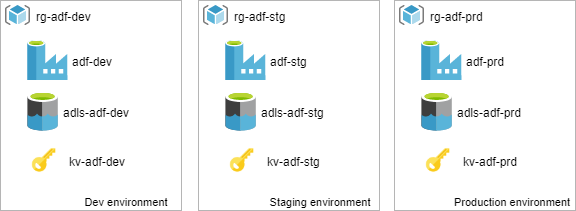
The picture above illustrates the importance of standardization and naming convention. All thee environments do not just look similar, they are created and named consistently. The most important aspect is that strict naming is a base for further automation, scripting and DevOps.
Continue reading…Azure Data Engineer Certification Tips
Recently I passed exams related to such certification and since then there is a flow of related but often-repeated questions. Over time, they are crystallized into a post in QA format, which hopefully can be helpful for someone who wants to pass this Microsoft certification. So, the questions are:
What kind of questions can I expect in the exams?
The Azure Data Engineer certification, in a contrast to SQL Server related exams, is less technical and more about understanding concepts of various services, their weak and strong sides and at what circumstances and for what requirements those services can be applied.
Obviously, because of the signed NDA, I cannot disclose real questions. However, as was being said, the main subject of exams is to ensure that the candidate understands not just services, but how they must be used, so he has a clear idea what is the difference in:
- Various Databricks node types and tiers
- Five different Cosmos DB APIs
- Azure Streaming Analytics windowing functions
- etc etc
I suggest to watch two related MS Ignite sessions:
- Exam Prep DP-200: Implementing an Azure Data Solution
- Exam Prep DP-201: Designing an Azure Data Solution
These sessions are led by Microsoft Certified Trainers (MCT), experienced in delivering content on these topics. The videos will not give the knowledge to pass exams, however, they will give a clear explanation about exams, the format, the expectations and strategies to prepare.
Continue reading…Azure Data Factory and REST APIs – Managing Pipeline Secrets by a Key Vault
In this post, I will touch a slightly different topic to the other few published in a series. The topic is a security or, to be more precise, the management of secrets like passwords and keys.
The pipeline created previously finally works. It ingests data from a third-party REST source and stores it in a data lake. However, to be authorized by REST the client id and client secret stored in a web activity configuration as a plain text.
The solution will be improved and become more secure by adding the Azure Key Vault to the scene. This service can be used to securely store and tightly control access to tokens, passwords, certificates, API keys, and other secrets. Also, this post will cover the security of inputs and outputs in activities.
Continue reading…Azure Data Factory and REST APIs – Mapping and Pagination
In this blog post I would like to put a light on a mapping and pagination of a Copy activity which are often are requirements for the ingestion of REST data.
Mapping is optional for data sources, like relational databases, parquet or csv files, because the incoming dataset contains an inherited structure, so the Data Factory is smart enough to pick it up and set as a default mapping.
However, to ingest hierarchical data like JSON or REST and then load it in as a tabular format an explicit schema mapping is required. In the previous blog post – Azure Data Factory and REST APIs – Setting up a Copy activity – such mapping was not provided yet explicitly. As a result, ADF was not able to write an incoming data streams in a tabular form and created an empty csv file. This post will fill such gap. Also, it will cover pagination which is also a common thing for REST APIs.
Prerequisites
- REST API Data source. I use Exact Online SaaS service in this post as an example.
- Azure Storage account.
Azure Data Factory and REST APIs – Setting up a Copy activity
In this blog post, I would like to show how to add and configure a Copy Activity which will ingest REST data and store it in a data lake. The REST API used as an example in this post is secured with OAUTH2 authentication. It requires a Bearer token to be obtained and passed as an authorization header. Such a technique was already demonstrated by me in a previous post of the series: Azure Data Factory and REST APIs – Dealing with oauth2 authentication.
Prerequisites
This post does not cover the creation of a storage account. To proceed, an Azure Data Lake gen2 blob container has to be created because it will be used later as a sink destination by a Copy activity.
How Copy activity works
To use a Copy activity in Azure Data Factory, following steps to be done:
- Create linked services for the source data and the sink data stores
- Create datasets for the source and sink
- Create a pipeline with the Copy activity
The Copy activity uses input dataset to fetch data from a source linked service and copies it using an output dataset to a sink linked service. This process can be illustrated as a visual flow:

In the example picture two linked services created: REST and Azure Storage They act just like connection managers in SSIS.
Continue reading…