Azure DevOps for SQL Server DBAs. Part 2 – Automating Deployments
In the previous post of the series – Azure DevOps for SQL Server DBAs. Part 1 – Creating a Database Project I’ve covered the very starting point – a transformation of a collection of the database objects into a solid deployable unit – the DacPac file. This post is the next logical step – how the DacPac files can be delivered to the group of on-premises SQL Server instances in an automatic, consistent, and efficient way. So, the topic of this post is Azure Pipelines – the CI/CD subsystem of Azure DevOps.
What is Azure Pipelines?
In short, Azure Pipelines is Microsoft’s primary Continuous Integration and Continuous Delivery offering. With Azure Pipelines, DBAs can automate and orchestrate tasks like:
- Build the database project
- Run the static code analysis to detect T-SQL issues, like syntax errors, or even bad practices
- Run unit-tests
- Configure approval gates
- Distribute the database objects among the instances
The items listed above can already be convincing enough but what is the conceptual value behind them?
A few examples:
- Redeployability – Any member of the team can contribute to the codebase by submitting the pull request and any member of the team can trigger the pipeline to deliver those changes to the destination targets. The general idea is – the deployment process is a packaged and reproducible routine that can be repeated at any moment. There is no more constraint in a form of a team member “who always does that”.
- Traceability – Azure DevOps maintains logs nearly for everything. New code contributions, PR approvals, triggered releases… All these operations and many others are logged, and the retention period can be set to years.
- Security – Azure Pipeline can act as a bridge between environments. Even if developers cannot access some sensitive groups of servers, the pipeline can do this. It can deliver deployment artifacts to the secured instance and log the deployment progress.
The common story
Many of us witnessed manual deployments during the midnight overtimes or at the weekend. When the deployment artifact is prepared by “Devs” as the zip archive with instructions in a text file and a bunch of SQL scripts. So, then “Ops”, who normally have an access to the production environment must place targets and sign-off.
The problem with such an approach is communication and ownership. When something is going wrong, the “Ops” guy sends an email that deployment was failed and signs off because that failure is not (really) his problem, it should because of the scripts, instructions, etc.
At the same time, sometimes instructions of “Devs” are not clear enough and their development sandboxes anything but not how the production environment is organized, so the script is not transportable. However, Devs will argue that they cannot reach production machines so Ops are the owners of the deployment failures because they keep production gates closed.
Azure Pipelines (or any other mature CI/CD tool) resolves this problem by automating and packaging the delivery. The deployment process can be modeled and tested on QA and Acceptance environments to catch issues in the early stage. Deployment to the production can be configured to run at a non-business time with the automatic rollback in case of failure. Developers can fine-tune release scripts. The pipeline becomes more and more mature and gains the trust not only of Devs and Ops but acts as the foundation for other improvements.
How can cloud-hosted Azure Pipelines reach on-premises targets?
Azure Pipelines is a SaaS product that runs somewhere in the data centers of Microsoft. To reach targets It uses a concept of agents as intermediate proxies. The agents can be hosted in Azure and on-premises. And just like in the picture below, the Microsoft-hosted agent is mainly to deal with targets that are directly in a sight of this agent. Think of various cloud services. It also can be used to run builds of the code though, since this stage does not require direct contact with destination targets.

In the case of on-premises targets, the solution is to use self-host agents. They act as the on-premises gateway to Azure Pipelines by establishing outbound HTTPS connections. Because such agents have a line of sight to on-premises destination targets, they can arrange a direct connection to them and then do real work – run tasks, deploy artifacts, publish test results back to Azure DevOps, etc.
I do not include installation steps, because such a topic deserves a separate post and other parties did a great job covering this process:
- Self-hosted Windows agents – Official documentation
- How to create and configure AzureDevops Pipelines Agent – alternative guide by DevArts
- Set up your laptop as an Azure DevOps agent to test SQL Server deployments – descriptive article by my colleague Kevin Chant
Self-hosted agents and deployment targets authentication
Another aspect to take into account is authentication. Windows-based agents are mostly configured to run as the service. When the agent connects to the target it uses the service account credential to be authorized:

Therefore, the agent account should have permissions to deploy DacPacs on the target database servers. Sounds simple. However, there is a catch – if the agent is in use by an entire organization this means that everyone is in the organization can push changes to the target database via pipeline.
If shared self-hosted agents are the only option, the workaround can be in the use of SQL Server authentication. In such a case, the password can be stored in Azure DevOps as the “secret variable” or in Azure Key Vault and retrieved by the pipeline to get authorized to run the deployment.
A more secure option for DBA teams is to have their own, isolated, and locked agent pool which will be used only by the SQL Server DBAs team. Further in this post, I will use this model of security.
Continue reading…Azure DevOps for SQL Server DBAs. Part 1 – Creating a Database Project
Azure DevOps as the tool and DevOps as the culture are hot topics these days. Traditionally, such methodology and related tools are heavily in use by developers. However, the tooling can also be helpful for operational roles, like SQL Server DBA. In a coming series of posts, I will do my best to show how DBA teams can benefit from Git repositories, deployment pipelines and continuous delivery of database objects like maintenance stored procedures, and SQL Server Agent jobs.
So, why are Git and versioned database projects needed for DBAs?
SQL Server DBA teams have to manage dozens, sometimes hundreds or even thousands of SQL Server instances. Often these instances are built in an automated way. They have the same set of disk drives, the same layout of folders, the same set of SQL Agent jobs, and often maintained using the same maintenance logic, so tables, stored procedures, etc.
The maintenance logic can consist of in-house and third-party code. Think of Ola Hallengren backup procedures, Brent Ozar first responder kit best practices checkers, sp_WhoIsActive of Adam Machanic, and so on. Some shops place such code to master or msdb system databases, however, such an approach is not supported everywhere. Another, and in my opinion safer way is to keep DBA’s objects in a separate database, for instance [dba] or [dbadb]. Further in this post, I will focus on a second approach: a specialized dbadb that exists on every managed database instance and acts as the container for DBAs assets.
So why source control? Naturally, at some point, the database [dbadb] must be updated. For instance, you have a new business requirement and want to update on all instances a stored procedure that checks for the existence of some login; another example, a new version of First Responder Kit released and you want to push it to all database instances; another example is a mere bug fixing – one of your colleagues found a bug in a frequently running job and patch should be pushed everywhere and soon.
If all maintained servers can be counted by fingers of one hand, the updates still can be deployed manually using SSMS. However, even in this case, there are drawbacks:
- Sometimes not all instances receive an update consistently due to human mistakes
- You do not know who updated the code and when
- The database objects are overwritten in [dbadb] and there is no maintained history, nor previous versions
Therefore, 2020 is a good year to think about DevOps practices and tools like Azure DevOps or GitHub, deployment pipelines, and Git as a source of the truth for your code and all related changes in it. In a such case, the source code is controlled by Git. When the team is ready to push changes to managed targets, it creates a release branch. Such a branch triggers the deployment pipeline, which compiles a set of SQL scripts into the DacPac and pushes it to the destination SQL Server instances.
While It can sound complicated, visually, the workflow illustrated this way:

Such an approach brings the following benefits:
- Source code stored in Git means out of the box code versioning, history, rollbacks, lightweight branches
- Quality gates: Pull requests, four-eye approval policies, static code analysis using SonarQube, etc
- Consistent deployments, so, no human factor, each team member can trigger deployment pipeline and the deployment will pushes changes the same way
- Free, lightweight, and cross-platform tools like Azure Data Studio and Visual Studio Code have a native Azure DevOps and GitHub integration
This blog post is about the very first step of a staircase: get a database project created. We will place the stored procedure for further distribution. And finally, we will commit it to the source control. Let’s start by setting up the tooling that is needed for this journey.
Continue reading…Azure DevOps – Team Conventions and Standards
This is a second post in an Azure DevOps series related to team agreements and standards. In a previous one I’ve illustrated a practical implementation of a branching strategy using the YAML pipeline. This post is more about other important team decisions: a selection of the branching strategy that suits team needs, repository naming convention, folders structure, and naming of the pipelines.
Why are development team agreements important?
Imagine that you are part of a mid-size software development team. You and the other six developers have sharp skills and good intentions to get the product delivered in the best way. At some, point you realize that nearly every member has his own and mostly very rational interpretation and view on how git branches should be arranged, how folders should be structured, how database views should be named, and so on. That is a good moment for a team to initiate self-organization by setting up a few meetings and discuss and then define team agreements.
The most productive and successful software development teams are those who managed to agree on one shared thing – consensus. A consensus that was discussed and sincerely agreed by an entire team gives a feeling of inclusiveness, that all members being heard and their input is evaluated into a set of conventions.
A few examples of such topics to be discussed and agreed upon:
- Git branching strategy
- Repository naming convention
- Repository folder structure
- Deployment pipelines naming convention
- Code formatting and comments
- Database object naming conventions
Let’s discuss some of these items.
Continue reading…Azure DevOps – YAML pipelines and branching strategies
Development teams have various forms of internal agreements about internal in-team cooperation. These agreements usually cover topics like branching strategies, policies, naming conventions, folder structures. In this post, I would like to touch one of them – YAML pipelines in the context of the branching strategy. Or, to be more precise, how to build a shared pipeline that will be used in multiple scenarios: building and releasing the code in various environments and as a build policy validation gate.
Branching strategies
With time Git became a de facto standard for the source control, team collaboration, and code contribution. To set up a consistent way of using such a tool, teams have to define some standards of cooperation, like naming conventions, repository structure, and especially: a suitable branching strategy from a variety of popular choices: Git Flow, GitHub Flow or Release Flow.
Further in the post, I will stick to a Release Flow. However, there is no good or bad choice. Every team has to discuss and choose the one that fits best.
From a high-level point of view the Release Flow branching strategy can be illustrated this way:

- It has a single collaboration branch – master.
- The changes performed in feature branches (topics) and delivered to a master branch by raising a pull request which contains quality gates like:
- Build policies
- Unit testing
- Static code analysis
- Peer reviews
- Release branches created to deliver the code to deployment targets
Azure Data Factory & DevOps – Advanced YAML Pipelines
In this post I would like to touch again modern Azure DevOps YAML Pipelines. It will be an extension of the previous one – Azure Data Factory & DevOps – YAML Pipelines. After it was published, YAML Pipelines moved from a preview to a general availability state. So, it is a good time to talk on what next and cover more advanced topics, such as pipeline templates, parameters, stages, and deployment jobs.
Prerequisites
Source Control enabled instance of ADF. The development environment should have already a source control integration configured. This aspect was illustrated previously in a post: Azure Data Factory & DevOps – Integration with a Source Control
Basic understanding of YAML Pipelines. Especially, in a combination with ADF. The content of Azure Data Factory & DevOps – YAML Pipelines is a nice starting point. I will expand the initial idea and refactor the code of that post.
The next steps
While the previous post shows basic scenarios of YAML it has still a “one-file” implementation, without any code re-use, approvals, and splits into stages. These issues will be addressed one-by-one now.
Parameterized templates
The primary purpose of the Azure DevOps YAML Pipeline templates is a code re-usability. Think of them as a mimic of stored procedures in SQL Server. The parametrized template acts similarly to a stored procedure with parameters. There is another function though – the template can be set as a mandatory one to be inherited so it can act as the security or control protection of what is allowed in the inherited pipeline. In this post I will focus only on a code re-usage. Below is an example of how one pipeline “re-uses” the same template twice with different parameters – to deploy ADF to staging and production environments:
stages:
# Deploy to staging
- template: stages\deploy.yaml
parameters:
Environment: 'stg'
# Deploy to production
- template: stages\deploy.yaml
parameters:
Environment: 'prd'
Stages
Stages act like logical containers for pipeline jobs. For instance, a build stage triggers jobs related to a build process, the deployment stage consists of some deployment jobs and so on. Stages also needed in case if the pipeline must be paused during the execution for external checks. Think of approvals, artifact evaluations, REST API calls, etc.
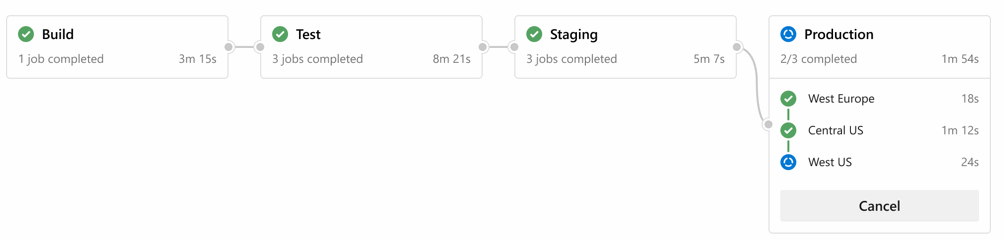
Deployment Jobs
Deployment jobs are special types of regular jobs. They provide a few extra benefits:
- various deployment strategies.
- maintain specific deployment history for further auditing.
- mapped to “environments”, this unblocks possibilities for setting approvals.